
Part 3 of the series — After building and load balancing our AWS infrastructure, it’s time to monitor it like a pro.
Introduction
After setting up our scalable AWS infrastructure using Terraform and integrating it with an Application Load Balancer (see Part 2), the next step is observability.
In this blog, we’ll use AWS CloudWatch Alarms and SNS notifications to monitor:
- EC2 CPU Utilization
- Auto Scaling Group (ASG) health
- And alert us by email
Architecture Overview
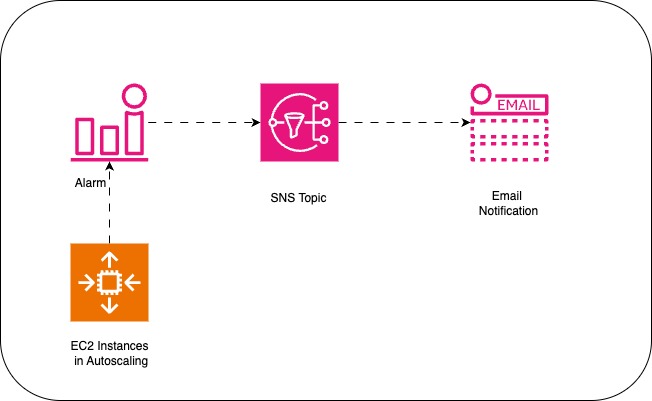
Here’s what we’ll build:
CloudWatch → SNS Topic → Email Alerts
Monitor:
- EC2 CPU Utilization
- ALB 5xx errors
- Auto Scaling Group health
Notify:
- Via SNS topic
- Subscribed email
Terraform Module Setup
We’ll create a new module under modules/cloudwatch-alarms/.
Key resources:
aws_cloudwatch_metric_alarmaws_sns_topicaws_sns_topic_subscription
Folder Structure
Step-by-Step Implementation
1. Define CloudWatch Alarm Module: modules/cloudwatch-alarms/
- SNS Topic
- CPU Alarm for ASG
- ALB Target Group Health alarm
2. Reference it in environments/dev/alarms.tf
module "cloudwatch_alarms" {
source = "../../modules/cloudwatch-alarms"
sns_topic_name = "infra-monitoring-topic"
notification_email = "your_email@example.com" # replace with your email
ec2_asg_name = module.ec2_autoscaling.asg_name
}3. Apply the changes.
terraform init
terraform plan -var-file="terraform.tfvars" -out=alarm.plan
terraform apply alarm.plan
Validation Steps
- Go to CloudWatch > Alarms > Your Alarm.
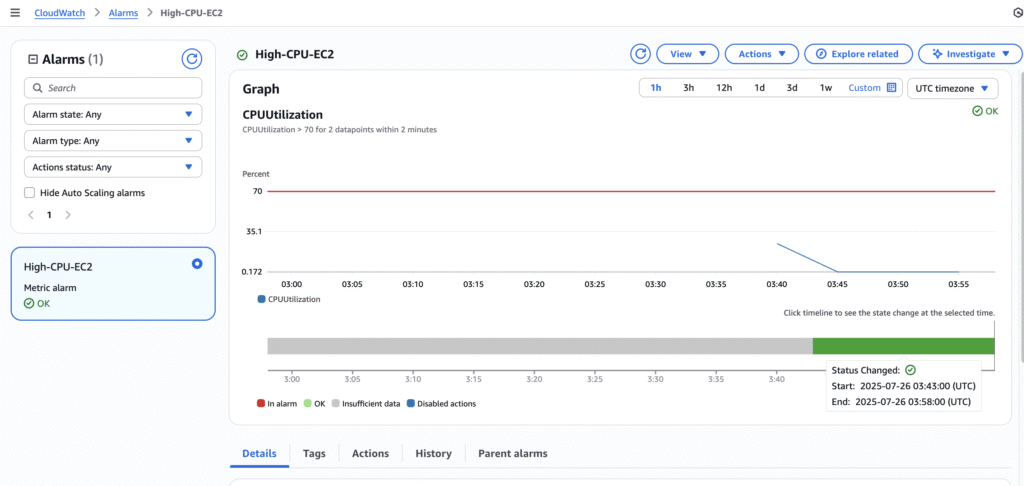
2. Manually increase CPU load or stop instance. I used this bash script and executed it in one of the EC2 instances.
#!/bin/bash
# Number of CPU threads to stress (adjust as needed)
CPU_THREADS=2
# Duration to keep the load (in seconds)
DURATION=300 # more than 2 minutes to ensure atleast 2 datapoints
# Install stress if not already installed
if ! command -v stress &> /dev/null; then
echo "Installing stress tool..."
sudo amazon-linux-extras enable epel
sudo yum install -y epel-release
sudo yum install -y stress
fi
echo "Starting CPU load using $CPU_THREADS threads for $DURATION seconds..."
stress --cpu "$CPU_THREADS" --timeout "$DURATION"
echo "CPU load completed."
3. View the alarm for EC2 CPU or ALB health.
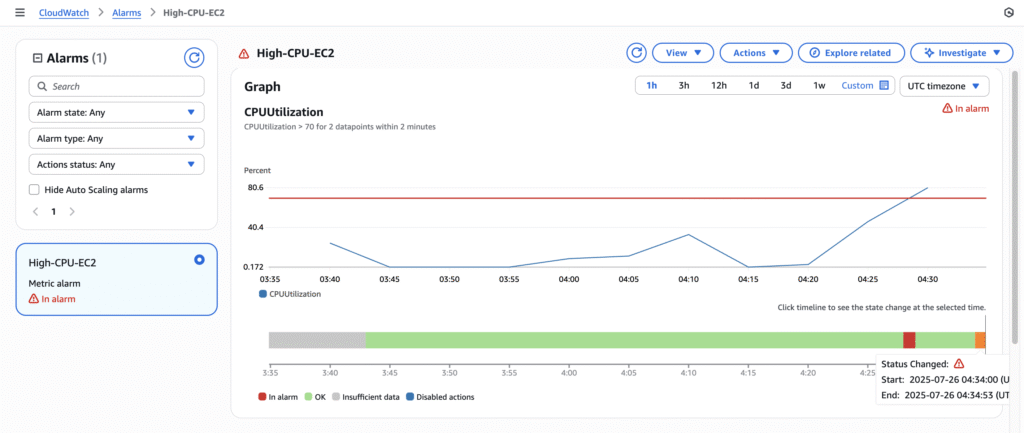
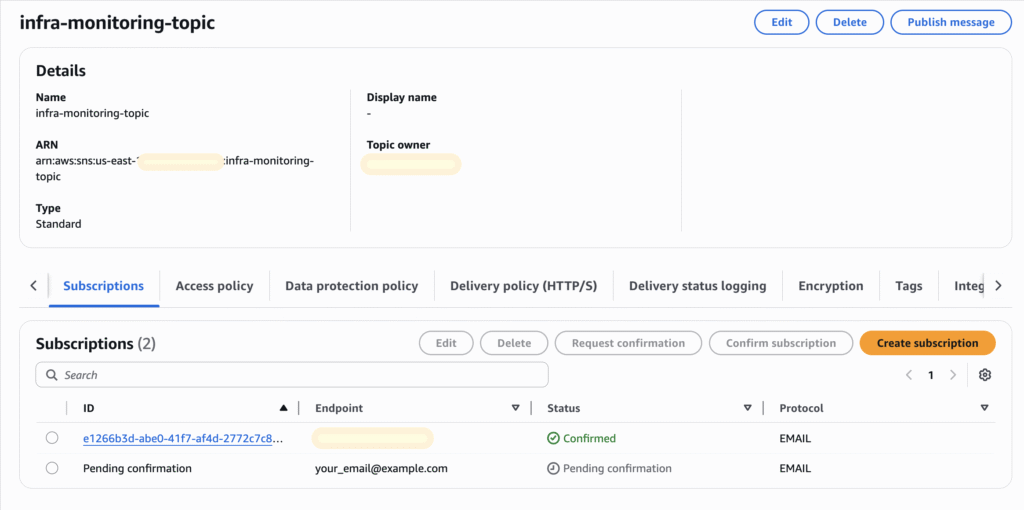
4. Make sure subscriptions are confirmed
5. Receive alert email from SNS.

Troubleshooting Tips
- Alarm stuck in
INSUFFICIENT_DATA? — Wait 5–10 mins or adjustevaluation_periods - Email not received? — Confirm SNS subscription confirmation was clicked.
- No ASG name? — Ensure
outputs.tfhas:
output "asg_name" {
value = aws_autoscaling_group.this.name
}Key Takeaways
- Monitoring is non-negotiable for production-ready infrastructure.
- With Terraform, you can version-control and scale your alerting logic.
- You’ve now added resilience to your AWS infrastructure.